Understanding Copy on Write
In a previous article we saw the difference between reference and value types in Swift. Let’s look at the memory management a bit closer!
Heap, Stack, value types and reference types
First an example :
struct MyStruct {
let someObject: NSObject
}
let myInstance = MyStruct(
someObject: UIView()
)When creating myInstance I am first creating a pointer to a UIView (the actual data of UIView is stored in the heap). Then I am creating an instance of MyStruct in the stack which contains the pointer previously created.
In the previous article we said that value types are stored in the stack and reference types in the heap. Well it is mostly true but not entirely. Indeed classes are allocated on the heap but some value types might also be stored on the heap.
class MyClass {
var integer: Int
}
let myInstance = MyClass(integer: 1)Here myInstance is an instance of class so logically its data is stored on the heap. And here the data is an integer which is a value type, so in fact not all value types are stored on the stack.
In fact the best way to understand what is stored where, is to understand what the stack and the heap are used for. To put it simply the stack contains what the program needs to run at any given moment, so the function it is currently running, its arguments and any local variable. While the heap contains everything else. But keep in mind when you are manipulating a class you are manipulating a pointer. Which means the pointer is stored in the stack for the time you are using it, while the data remains in the heap.
One major difference between the two, is that the stack is ordered while the heap does not have to be.
The case of Array
The Swift language is peculiar when it comes to this. Because many types that usually have reference semantics, are provided with value semantics in the Swift standard library. In fact this is the case for every collection type in the standard library.
Whenever we manipulate an array in Swift, we take for granted that it provides value semantics for the elements it stores.
var x: [Int] = [1]
var y: [Int] = x
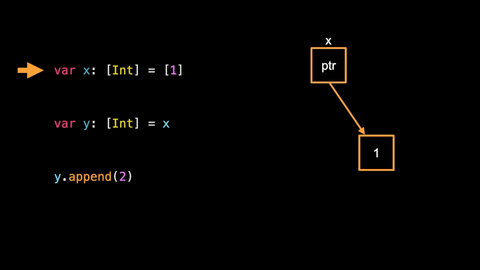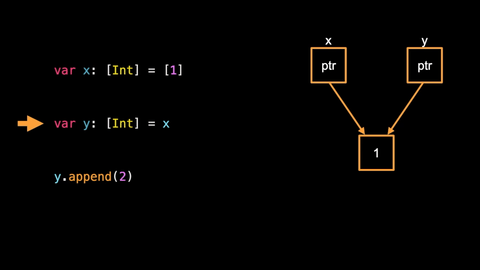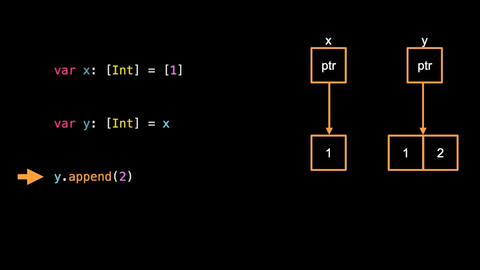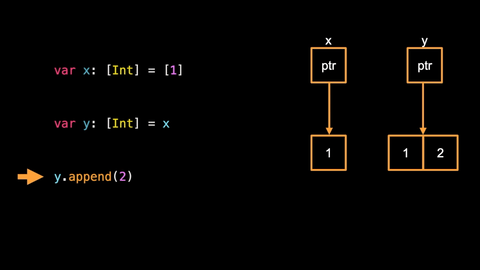
y.append(2)
print(x, y) // prints [1] [1, 2]In many languages the array type is a reference type, and the above code would print [1, 2] [1, 2].
In fact any data structure with a variable size has to be stored in the heap. Indeed since the stack has to keep its memory in a given order and its content can only be popped or pushed, to modify in place a variable sized data structure we would need to pop elements from the stack until we can pop the concerned data structure, modify it then push back everything. This would be extremely inefficient, for this reason in any programming language, dynamic collections of data are stored in the heap, which means they are manipulated using pointers.
If this is true, how come swift provides value semantics for arrays!? Well this is what copy on write (CoW) does.
When we execute the above code what happens is the following :
- we create an array on the heap containing the value
1. - we duplicate the reference to this array from the variable x to the variable y
- we copy on write: before adding an element to the storage on the heap we duplicate it elsewhere so that we can modify
ywithout impactingx. And then we modify our new storage by appending another element.
This mechanism enables us to provide value semantics for properties stored in a class.
You might not always have to reimplement the standard library in your application, but this can still be a great tool if you want to provide value semantics for a class. This might be the case when you are using an objective-c API, or any API providing a class for something you would wish to use as a value type.
Implementing Copy on Write
Copy on write seems pretty magical because it enables us to avoid duplicating values around when we just need to read them, and still enables us to manipulate a class like it is a value type.
Let’s try to create a class implementing copy on write in order to really understand how it works.
class SomeClass {
var value: Int
}In order to provide value semantics to this class while still storing data in the heap let’s wrap this into another data structure. And since we are providing value semantics and it is in Swift let’s use a struct (even if we could have used a class).
struct CoWSomeClass {
private class SomeClass {
var value: Int
}
init(value: Int) {
storage = SomeClass(value: value)
}
private storage: SomeClass
var value: Int {
get {
storage.value
}
}
}Accessing the stored value is simple, but writing to it is where things get tricky, let’s duplicate the storage like we said earlier.
extension CoWSomeClass {
var value: Int {
set {
storage = SomeClass(value: newValue)
}
}
}With this implementation we have managed to provide value semantics for our value variable.
But we need to always reallocate a new storage whenever we want to modify value.
This is necessary when multiple instances of CoWSomeClass use the same storage, but if we were to use only one instance CoWSomeClass we would not need to duplicate the storage at any change.
Fortunately for us Swift provides us with a really handy function isKnownUniquelyReferenced<T>(_ object: inout T).
Returns a Boolean value indicating whether the given object is known to have a single strong reference.
In other words the function returns true if and only if the instance’s reference count is 1.
Or in plain english it returns true if we are the only one using it.
Being the only one using a storage means that we can do our modifications in place :
extension CoWSomeClass {
var value: Int {
set {
if !isKnownUniquelyReferenced(&storage) {
storage = storage.copy()
}
storage.value = newValue
}
}
}And this is how you can implement copy on write. For a better perspective on the code let’s see it all in one piece.
// Actual CoW implementation
struct CoWSomeClass {
init(value: Int) {
storage = SomeClass(value: value)
}
private storage: SomeClass
var value: Int {
get {
storage.value
}
set {
if !isKnownUniquelyReferenced(&storage) {
storage = storage.copy()
}
storage.value = newValue
}
}
}
// Storage definition
extension CoWSomeClass {
private class SomeClass {
var value: Int
init(value: Int) {
self.value = value
}
func copy() -> SomeClass {
SomeClass(value: value)
}
}
}CoW and performances
You might think: this is great but there is no reason why you might want to implement CoW anywhere in your code.
Well it turns out CoW can also boost the performances of your structs.
To implement CoW with a struct we just have to turn it into a class and implement CoW for it.
struct SomeStruct {
var value: Int
}Would be implemented exactly like our example above.
Performances
In Swift function arguments are passed by copy and not by reference.
func myFunction(_ argument: SomeStruct) {
// Do nothing
}
var x = SomeStruct(value 0)
myFunction(x)In the above example two instances of SomeStruct are created: one at the declaration of the variable x and one when that value is duplicated to be passed into the function (This is true if the compiler does not inline the function, but inlining is a topic for another day).
A fair question for the performances would be: what makes an instance of anything take more or less time to duplicate? So naturally let’s look at the size of the data structure and the difference between using a value type or a reference type.
Let’s compare with different types:
- an
Int - a
classcontaining only anInt - a complex
struct - the same data structure as a
class
Our complex struct/class is going to be the following :
struct ComplexStruct {
var id: Int
var topics: [String]
var headline: String
var isHighlighted: Bool?
var title: String
var picturesUrl: [String]
var keywords: [String]
var publicationDateTime: String
var likesCount: Int?
var readingTime: Int
var isLiked: Bool?
var isNew: Bool
}For each type we are going to run 100 000 000 times a function only returning its argument like the one before.
func myFunction(_ argument: Type) {
return argument
}Where Type is going to be replaced by Int, IntClass, ComplexStruct or ComplexClass

| Type | Int | Int class | complex Struct | complex class |
|---|---|---|---|---|
| Duration (in ns) | 0.19 |
0.29 |
8.58 |
0.25 |
It seems that struct takes longer to duplicate as the data structure becomes more complex. While class keeps pretty much the same performances.
This makes sense since when duplicating a true value type you have to duplicate every piece of data into a new instance. While duplicating a reference type is only duplicating a pointer (and updating a reference count). You might notice I have called our ComplexStruct a true value type, this is to differentiate with something like Array which is a value type, because it has value semantics but it is build with copy on write, so the data is stored in the heap and accessed with a pointer.
This raises the question of the performance of implementing a CoW version of our ComplexStruct.
 This is the same exact performance we had with the
This is the same exact performance we had with the class implementation.
As we just saw, CoW can improve the performances for our complex structs, by reducing the time it takes for them to be passed into functions. But be careful when implementing it: as each performance improvement technique, you should always profile your app to make sure this is really an improvement overall. Also CoW brings more complexity to your codebase so you might want to be cautious with it to keep your app maintainable.
Takeaways
If you have been a Swift developer for some times now, you have probably already heard about class performing faster than struct or the other way around. As we saw from our benchmark, both statements are true to some extent, if you manipulate really simple data structures you will have better performances using struct, and the other way around as your data structure becomes more complex. But this is not a good way to choose between structor class. You must always focus on the semantics: do you want value semantics or reference semantics? And if a performance issue arises with your structs then you might want to think about using copy on write. But do keep in mind CoW brings more complexity to your code base, and as with all performance improvements, you should profile your app to make sure it actually has a positive effect on the performances.
But CoW is not limited to high performance programing as we have seen in the begining of the article you might also use it to provide value semantic for a framework entity that is class based.