on
HQ Trivia reverse engineering
Launched on the very end of 2017 by the creators of Vine, HQ Trivia is making a lot of noise on the tech scene. Its instant popularity and disruptive concept (a mobile app active a few minutes a day) turned this app into a phenomenon closely watched by investors. A few months of existence, and it’s already valued at more than 100M$ ?.
However as developers, we were also impressed with the ability of this emerging app to offer a smooth real-time experience, to a million of concurrent players. Browsing through the web, we did not find any clue regarding the technologies they were leveraging to power this. It was time for us to look under the hood.
Inspecting the traffic
The easiest way for us to understand HQ Trivia working was to inspect the traffic resulting from the app. We plugged our phone on one of our everyday tool, Charles Proxy, and waited for the next show to happen.
Our first try taught us three things: they have a cool hype.space domain, as responsible developers they enable SSL on it, and setting up correctly your Charles certificate to enable the SSL proxy takes longer than a show.
We thus had to negotiate a second Charles dinner break (first show is at 9PM in Paris), but it was worth it. With the proxy correctly configured, all the HTTPS traffic of the application was immediately decrypted. Luckily for us, no specific security countermeasures, such as certificate pinning, was in place.

The app is short polling (on a 5s basis) the route /shows/now. That’s kind of weird as /shows/now returns the time of the next show (and the prize for the most greedy of you). They could have simply muted the request until this time, but the app would have missed any advanced show. It looks like they chose a huge flow of requests over missed shows. Pushing through silent notifications or websocket could have a been a more efficient choice.
- When the time has come,
/shows/nowhas a new broadcast object, with two exciting urls:stream_urlandsocket_url - The authentication is pretty simple, a long-lived token in the Authorization header. It makes it easy for us to replay/forge requests.
- And… that’s all for HTTP traffic. No quiz question or answer in sight.
While we were pleased that this simple inspection gave us the first elements to understand HQ, there was still no sign of the questions and answers we secretly craved for. It was time to go further and see what we could extract from the stream and socket.
Video break
The video frames not showing up in Charles, we knew the stream was not using the HLS (HTTP Live Streaming, developed by Apple) we were used to play with in our beloved myCANAL. The stream url indeed leverages RTSP (Real Time Streaming Protocol). Warning, do not confuse it with RSTP (Rapid Spanning Tree Protocol), otherwise, speaking from experience, you will unnecessarily try for an hour to understand how you can base video streaming on a network loop-free logical topology. RTSP is indeed a coherent choice if you want to support older Android devices.
What’s interesting about the stream_url is that it does not depend on the show, it’s always the same. So we wondered, what is happening on this link between the shows? The simplest way to answer was to open VLC and enter the stream URL rtsp://edge-hq-uk.hype.space:1935/live/wirecast_medium (yes this awesome player can play everything). And there were the cartoonish colored bubbles floating on a blue background. HQ Trivia never really sleeps.
Socket
In order to know what was happening on the socket, we developed a small ruby script, polling the endpoint /shows/now, just like the mobile app. Once this script gets a broadcast object with a socket_url, it tries to connect to this websocket and simply log all the messages. Bloated by “interaction” messages (powering the frenetic chat of the app), our log also contained what we aimed at since the beginning, “question” messages and “questionSummary”. Everything was there, from the central question/answers texts, to the number of votes for each answer.
We then spent a bit of time augmenting our script with business models to parse the socket messages. Once able to turn messages into objects, we decided to daemonize the script and set it up on a server. So we reached a point where we were able to interact in real time with the socket.
From there, we considered storing trivia as the most useful thing to do. Pleased to see our small database growing, we also introduced a Twitter integration to our script: https://twitter.com/HQTriviaScribe (237 followers and growing ?). It was a good reminder, for us geek folks, that you don’t always need a hardcore technical achievement to interest people.
Bot player
Of course, we did not stop there and gave a shot to create a bot able to play HQ. We started by developing a script able to benchmark our player implementation, running it against a set of trivia, and collecting the results.
We designed our naive bot to mimic the behavior of a human being confronted to a question she can’t answer: rush for Google. But contrary to a human being, our bot can’t make sense of the content retrieved by Google. So we opted for the simple metric “Number of results” on a request concatenating question and answer. The higher this number is, the stronger the correlation between the question and the answer.
Our evil plan seemed perfect, until after a few Google requests fired, our bot stopped to work because Google started asking it to fill CAPTCHAs to prove… it was not a bot. We could have spent hours circumventing this check, but it proved easier for us to simply switch from Google to Bing.
We ran our Bing bot against 10 shows, and ended up with a rather mediocre performance. Its best score was 3 rounds, for an average success rate of 40% (on all questions, end of game / hard ones included). As a comparison, a complete random choice would have an average success of 33% (each question has 3 propositions). You might be better served by your intuition than a bot like this.
Disappointed by the results of BasicBingPlayer, we decided to create SmartBingPlayer, loaded with two other tools. One was a simple trick to understand the NOT keyword of some questions, indicating they expect the answer with the lowest correlation. The other tool was to leverage the Google Natural Language API to parse the entities of the question, to simplify the request sent to Bing (asking it “size Michael Jordan”, rather than “what size is the former basketball superstar Michael Jordan?”). Full of confidence this bot would crush the game, we launched the benchmark. 45% of average success rate, high score of 5 rounds. Slightly better, but still a long way to go before having a chance to answer successfully 12 questions in a row.
We were quite frustrated to fail so far from our goal. There is no doubt that a program with more engineering would have performed well on HQ Trivia, Watson proved it in Jeopardy. However, we were pleasantly surprised to observe that questions crafted to be challenging for human beings, were also puzzling for search engine queries.
Here comes the app
Another way to see how the app is working is to take a look directly at the app itself, and see what makes it tick. HQ Trivia is available on both iOS and Android, but it will be much easier to look at the Android version. The reason for that is that iOS apps are compiled and the code is transformed to a binary format. Meanwhile, on Android, the code inside the app is still in a format legible to a human reader.
We already described how to dissect an Android application in a previous blog post on Pokémon Go but let’s walk you through the basics.
What goes into an app?
First of all, the file format of an Android application is an .apk file. This is what the Play Store sends to your device when you want to install a new app. Now you can’t ask the Play Store to give the .apk file like that, but third-party websites (easy to find on Google) allow you to download any (free) app available on the Play Store, which could be used to install an app that has not yet been released to your country for example. Now you should never install on your device an app from a source you don’t trust, but here we are just looking at the APK, not installing it. In our case, we downloaded an APK for version 1.0.4 of HQ Trivia, which was the latest version in early February.
Now that you have your APK, you might wonder what you can do with it… Turns out, this is not an exotic file format, it is just a simple .zip archive under a different name. So you can unzip it with any tool you usually use, and you would face the following files:
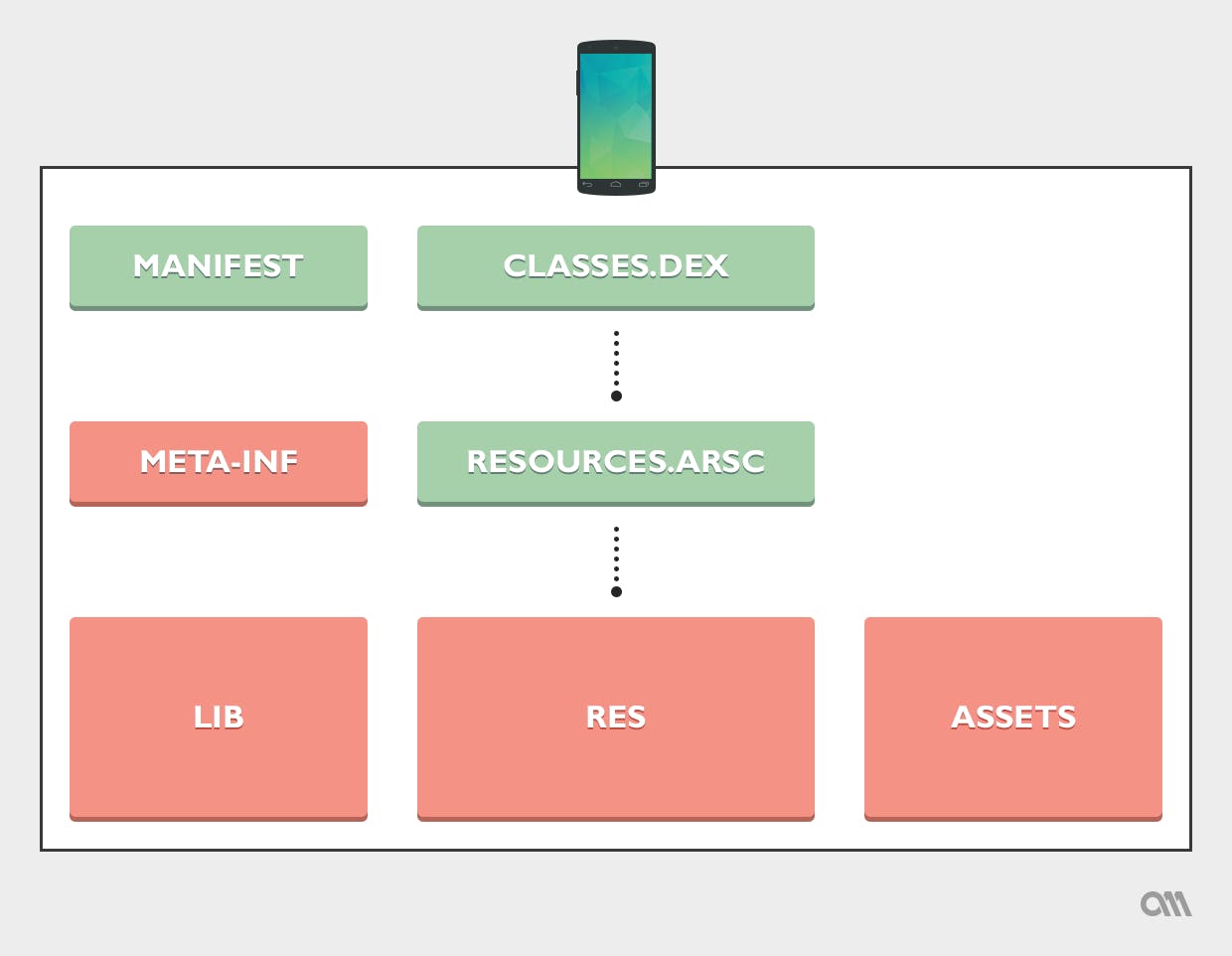
Some of those files are of little importance right now :
META.INFis a folder containing some metadatalibwill contain some native libraries that the app code can invokeresources.arscis a file format specific to Android, that links the code to the app resourcesresandassetscontain the app’s resources (like images, sounds, wording, layouts, …), which are nice to have, but give us no indication about the inner workings of the app
So the two most interesting files to us are the manifest (named AndroidManifest.xml) and classes.dex. The first one serves as the identity card of the project, specifying its name, icon, version, permissions, device restrictions and all the components of the app. And classes.dex is where all the code of the app will reside.
Now both of those files are in a binary format, unreadable by a human. Thankfully, Android Studio provides us with a first option to see what’s inside, with a tool named “Analyze APK” (available under “Build > Analyze APK”). It shows us something that looks like that:
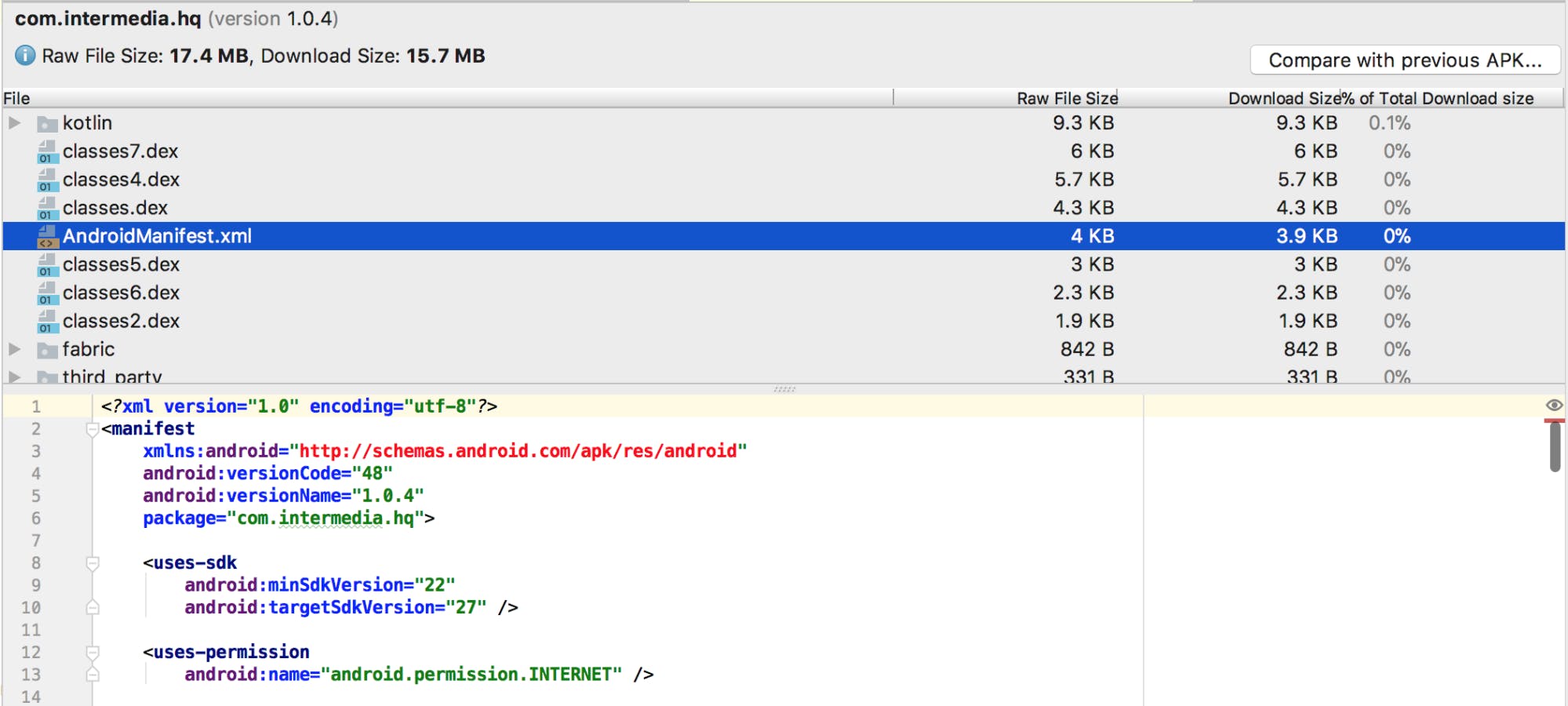
Now we can see a few things already:
- the Manifest becomes completely legible, which gives us a great entry point into the app (by describing its main components), but everything seems pretty normal inside. For example, there is no weird, unexplained permission required
- we can see a kotlin folder, that contains the Kotlin runtime classes, so it seems that the developers at HQ Trivia are toying with the latest tech (and who could blame them! Kotlin is amazing)
- we don’t have one classes.dex, but 9! This is possible thanks to a fairly recent addition to the Android toolbox. When it was first developed 15 years ago, Android was never intended for the modern smartphones and tablets, so an engineering choice put a limit of 65,536 methods for an application. When developers started to hit this limit a few years after Android was available for consumers, it was too late to change the file format and, at the same time, offer backwards compatibility. So Google found an alternative by allowing projects to generate an APK containing multiple classes.dex files, each one limited to 65k methods. But even if it makes sense on the technical side, there should be no reasons for such a small app (in terms of features and screens) to require that many methods
- finally, if we look at the content of those classes.dex, we can’t see the code inside the methods, but only what those methods are:
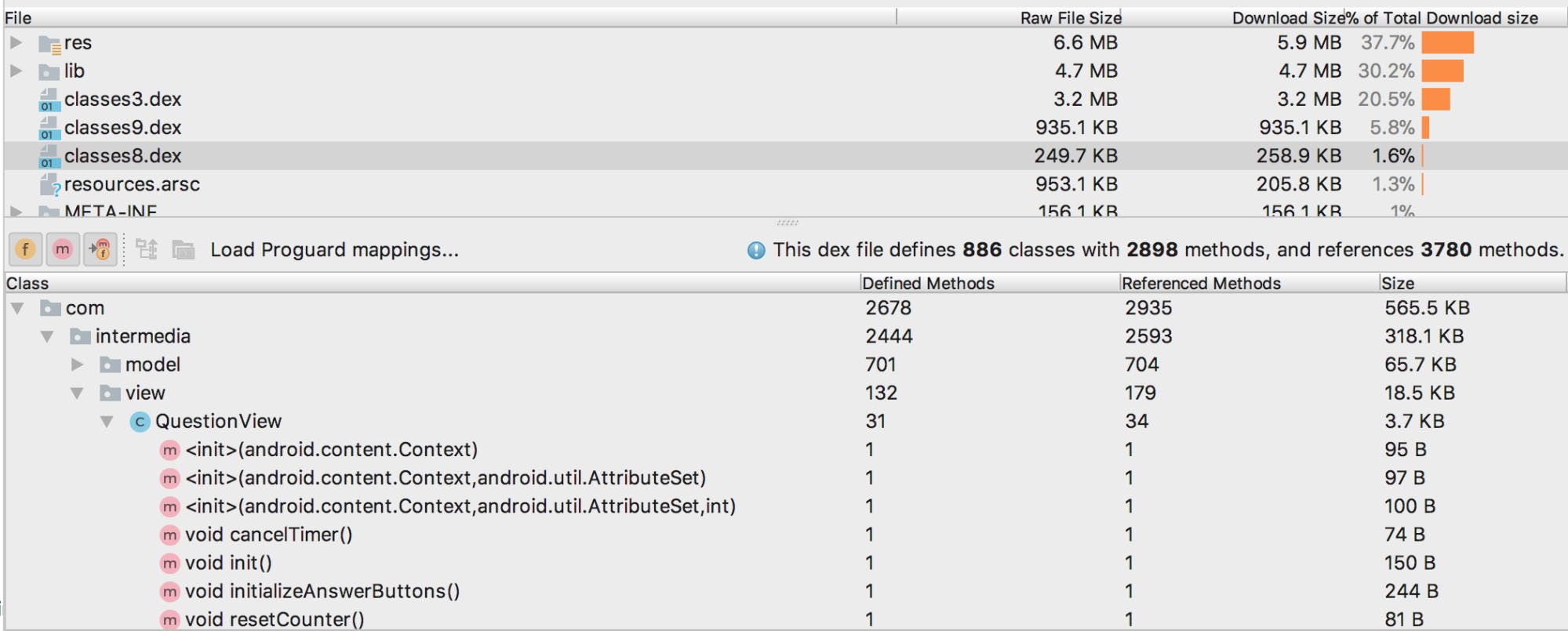
And that gives some more information: no effort was made to obfuscate the code inside the application. The most common tool used for obfuscation on Android (Proguard) is also used for shrinking the code (by removing unused methods, fields, resources, …). So no obfuscation often means that no effort was made to reduce the memory footprint of the app, which in turn explains why a small app such as HQ Trivia would require using MultiDex.
No obfuscation is also great news for us: instead of having barbaric names for classes, fields and methods, we will be able to see the names the developers used. Without those names, the process of understanding how the app works becomes much more convoluted: you have to start by the Manifest, which gives you the components of the app. Then by exploring those components and looking at classes which cannot be renamed (classes from the Android framework), you can start guessing what tidbits of code do, and build from that knowledge to guess what the calling code does, and so on… This is an extremely tedious task and our interest in HQ Trivia would not have been enough motivation to go through this.
But now we are reaching the limits of the “Analyze APK” feature from Android Studio, since it cannot show us the code inside the classes. The best case scenario would be to be able to recreate an Android project, with readable code, that would compile and give us the same HQ Trivia app you can find on the store. And just going from the methods names is not going to be enough. So to keep going, we will need to use other tools. The next one in our arsenal is called Apktool.
Decompiling the project
Apktool will do a lot of things that will bring us closer to our objective: it will decompile the Manifest and other xml files to a readable format, it will revert resources.arsc to the R.java file that Android developers are used to, and it will also convert the classes.dex files to smali code. Smali is a bytecode format, close to the bytecode instructions given to the VM. Technically, you could read and write smali, but being so close to machine instructions, it is a pretty terse format (smali is Icelandic for Assembler, which should give an idea on how easy it is to read smali). But while we won’t use smali code directly, it will still prove useful later.
Now that we have used Apktool, we can create a new Android project, in which we can put:
- our decompiled Manifest
- the native libraries in the lib folder
- the resources and assets
- the additional files located in the apk (that Apktool will place in an unknown folder): they’re mostly files used by dependencies like Fabric or Crashlytics
And the only thing now missing is the source code.
In order to get source code that can be used by the Android toolchain, we will need Java or Kotlin code. To do so, we will have to chain two tools. First dex2jar, which will allow us to go from the Android dex format to a more standard Java format: a jar file. And then, from this jar, we could use any Java decompiler available (JadX, Procyon, CFR, …). But here, instead of installing and using all those tools ourselves, we will cheat and use an online tool that will do at the same time the job Apktool did earlier, and decompile the source code: http://www.javadecompilers.com/apk.
Now we can add this code to our project, and pray that it will compile. Unsurprisingly, it will not. Decompilers are not perfect and they won’t be able to work on all of the code. Different decompilers will have different results, they won’t fail in the same places, but we haven’t found any that was able to decompile the whole project with no mistakes.
Later on, we will see how we can fix those issues, but now we already have 90% of the code available to us, so we can already take a look at what we have.
Disclaimer: decompiling code does NOT give you the original code back. To make an analogy, if you were to translate some text from English to French, and then translate the French version back to English (without looking at the source document), you would obtain a text that could be quite different from what you had earlier.
When we’re decompiling code, we actually have better guarantees than when working with natural language: assuming a perfect decompiler, if we decompile and recompile a binary, we should get the same output. So if we were to recompile our decompiled code (after fixing the mistakes), since we are using the same assets and resources, we would get the same app as the one we started with.
On the other hand, we will be missing a lot of what the original project would look like: comments are not present in the APK and thus cannot be recovered. The build instructions or tests are also missing. So we can see only part of the original project, but since we’re interested in how the app is working, it should be enough.
First sample: code modified on compilation
Let’s take a first example, located in LoginActivity :

First of all, this is debug code: it should not be present in production. This is why you should minify your app before putting it on the store. Here it is a minor issue, since it is mostly dead code, but in other places, logs are active, and you should always disable logs in production.
Then, we see that Android Studio raises a couple of issues, with the number arguments of setVisibility in both branches of the if. This comes from Lint, that knows the values expected by setVisibility should be one of View.VISIBLE, View.INVISIBLE or View.GONE.
The warning here is to pressure you into using the constant names instead of their values. This is good practice in case the values of the constants were to change, but it also makes the code much more readable. But when compiling, the build chain will replace the constants with their values, to avoid a look-up, and when decompiling, the decompiler does not replace the number with the declaration: it would be quite painful to develop a decompiler that would be aware of the full Android APIs to be able to do this.
Finally, we can look at the condition: if ("external".equals("internal")). This looks like an obvious mistake: why would a developer write a condition that would always resolve to false? This is another decompilation artefact. If you were to look inside the BuildConfig.java, you would find the following declaration: public static final String FLAVOR = "external";. The original code in LoginActivity was if (BuildConfig.FLAVOR.equals(“internal”)) (or equivalent) and the decompiler replaced BuildConfig.FLAVOR with its value at the time of the build. So we can infer that the original project declares two flavors: external and internal, the second one being used for in-house testing. For users of the second flavor, they get an additional message on the login screen to inform them that the application they’re currently using is the one used for tests.
You can also find an equivalent code snippet in the MainActivity, so that the information is also available if you are already logged in. Those are the only two places where the BuildConfig.FLAVORvalue is used in the code.
Second sample: re-use of variables
Let’s take another example:

We can see that the decompiler added an unnecessary cast to HQGameResult, but this is not really an issue. The issue comes from the next line, where the decompiler tried to affect the getString result to paramJSONObject, which is the wrong type (JSONObject instead of String). Let’s take a look to the corresponding Smali code to understand how this happened:
# direct methods
.method public constructor (Lorg/json/JSONObject;)V
.locals 3
.annotation system Ldalvik/annotation/Throws;
value = {
Lorg/json/JSONException;
}
.end annotation
.line 16
invoke-direct {p0}, Ljava/lang/Object;->()V
.line 17
new-instance v0, Lcom/google/gson/Gson;
invoke-direct {v0}, Lcom/google/gson/Gson;->()V
.line 18
invoke-virtual {p1}, Lorg/json/JSONObject;->toString()Ljava/lang/String;
move-result-object v1
const-class v2, Lcom/intermedia/model/HQGameResult;
invoke-virtual {v0, v1, v2}, Lcom/google/gson/Gson;->fromJson(Ljava/lang/String;Ljava/lang/Class;)Ljava/lang/Object;
move-result-object v0
check-cast v0, Lcom/intermedia/model/HQGameResult;
iput-object v0, p0, Lcom/intermedia/model/message/GameSummaryMessage;->gameResult:Lcom/intermedia/model/HQGameResult;
.line 20
const-string v0, "ts"
invoke-virtual {p1, v0}, Lorg/json/JSONObject;->getString(Ljava/lang/String;)Ljava/lang/String;
move-result-object p1
.line 21
sget-object v0, Lcom/intermedia/util/DateTimeUtils;->INSTANCE:Lcom/intermedia/util/DateTimeUtils;
invoke-virtual {v0, p1}, Lcom/intermedia/util/DateTimeUtils;->utcFromISO8601String(Ljava/lang/String;)Lorg/joda/time/DateTime;
move-result-object p1
iput-object p1, p0, Lcom/intermedia/model/message/GameSummaryMessage;->date:Lorg/joda/time/DateTime;
return-void
.end methodWell this looks nothing like what you are used to when you are an Android developer. Let’s take it line by line.
First we have this instruction on line 16: invoke-direct {p0}, Ljava/lang/Object;-><init>()V. Invoke-direct is a Dalvik bytecode instruction (you can find the full list here). It calls the method specified in the second argument (the init() method from Object) on the object in the first parameter (here: p0). p0 is a register that holds the 0th parameter, which here would be the object itself (this). p1 would hold the first parameter, which is the JSONObject. So this first instruction initializes the instance, which is akin to invoking the super constructor. Since this is a no parameter invocation of the super constructor, there is no need to write this in the source code, so the decompiler skipped this instruction.
Next, line 17 holds the following:
new-instance v0, Lcom/google/gson/Gson;
invoke-direct {v0}, Lcom/google/gson/Gson;->()VThose instructions create a new Gson object, puts it in the v0 register and initializes it. So far so good.
The next line becomes more tricky :
invoke-virtual {p1}, Lorg/json/JSONObject;->toString()Ljava/lang/String;
move-result-object v1
const-class v2, Lcom/intermedia/model/HQGameResult;
invoke-virtual {v0, v1, v2}, Lcom/google/gson/Gson;->fromJson(Ljava/lang/String;Ljava/lang/Class;)Ljava/lang/Object;
move-result-object v0
check-cast v0, Lcom/intermedia/model/HQGameResult;
iput-object v0, p0, Lcom/intermedia/model/message/GameSummaryMessage;->gameResult:Lcom/intermedia/model/HQGameResult;The first two instructions take the first method argument (the JSONObject, currently stored in the p1 register), calls toString() on it, and stores the result in the v1 register. Good!
The next instruction is pretty simple: it takes the class instance of HQGameResult and stores it in the v2 register.
So the contents of the register currently look like:
- v0 : new Gson()
- v1 : paramJSONObject.toString()
- v2 : HQGameResult.class
- p0 : this
- p1 : paramJSONObjectThe next instruction will call the fromJson method, from the Gson class, on the v0 register and with v1 and v2 registers as arguments. So the equivalent Java code would be:
new Gson().fromJson(paramJSONObject.toString(), HQGameResult.class)The following instruction (move-result-object) puts the result of this invocation in the v0 register, and then the typing is checked (check-cast). Finally, the iput-object instruction will store the result (from v0) in the gameResult field of p0 (which is this). So the final Java code looks like:
gameResult = new Gson().fromJson(paramJSONObject.toString(), HQGameResult.class);Good: this is what the decompiler gave us.
And now, the instructions in line 21 will show us why the decompiler gave us some invalid code:
const-string v0, "ts"
invoke-virtual {p1, v0}, Lorg/json/JSONObject;->getString(Ljava/lang/String;)Ljava/lang/String;
move-result-object p1Let’s recap what we have in these registers right now:
- v0 : new Gson().fromJson(paramJSONObject.toString(), HQGameResult.class);
- p1 : paramJSONObjectSo the instructions for line 21 will put the value “ts” in the v0 register, call getString on p1 (paramJSONObject) with v0 as a parameter (“ts”). And we store the result in the p1 register (which previously housed paramJSONObject).
And this is the reason why the decompiled code is incorrect. The VM registers have no type, and can thus be reused as long as the stored value is no longer necessary. On the contrary, the Java code cannot reuse any variable in the same way, since those variables will have types. If the variable is created in the body of the method, the decompiler gives it the Object type, so that it can reuse it just like the registers are reused in the bytecode (abusing casts in order to make it work). In this case, the variable being also a method parameter, its type is constrained by the method signature. The decompiler tried to reuse it, but this did not end well because of its type.
This behavior is very specific to the decompiler we used. The website javadecompilers.com currently only offers the Jadx decompiler in its “APK decompiler” menu. So this forced reuse of invalidly typed variables is specific to Jadx (and others like CFR) but is not a behavior exposed by others like Procyon, which is smart enough to create new variables with the right type when necessary.
Pause: looking for dependencies
Let’s take a break from looking at bytecode. As we saw when we discovered the amount of classes.dex files, this app contains a lot of classes. But this doesn’t mean that every single one was written by the HQ Trivia developers: like every good developer, they know they don’t have to reinvent the wheel and can use open source projects to accelerate their development efforts.
If we are able to identify what those dependencies are, we can delete every file that was added to the project through a dependency, and therefore only focus on the remaining files, that are specific to HQ Trivia.
This is especially important here since we know that our decompiler is not perfect (as we saw just before: it introduces invalid code to our project). So every dependency we can replace with its declaration will minimize the time we will spend fixing all those bugs.
Fortunately, HQ Trivia does not use Proguard, which means no obfuscation and no minification, so identifying libraries is going to be very easy. We just need to look at the different packages declared in the source code, and match those with known dependencies.
Only two packages seem to be specific to the app: com.intermedia (Intermedia Labs is the parent company behind HQ Trivia) and com.tendigi.hq.hqplayer (Tendigi seems to be a mobile development agency, and it looks they developed an Android media player specifically for HQ Trivia).
The rest is all fairly standard libraries.
The full list of the dependencies we found is not that interesting. But some dependencies have more of an impact than other. For example, we think that HQ Trivia has a dependency on
+--- com.google.firebase:firebase-messaging:11.8.0
| +--- com.google.firebase:firebase-iid:11.8.0
| | +--- com.google.android.gms:play-services-basement:11.8.0
| | | +--- com.android.support:support-v4:25.2.0 -> 27.0.2
| | | | +--- com.android.support:support-compat:27.0.2
| | | | | +--- com.android.support:support-annotations:27.0.2
| | | | | \--- android.arch.lifecycle:runtime:1.0.3
| | | | | +--- android.arch.lifecycle:common:1.0.3
| | | | | | \--- com.android.support:support-annotations:26.1.0 -> 27.0.2
| | | | | +--- android.arch.core:common:1.0.0
| | | | | | \--- com.android.support:support-annotations:26.1.0 -> 27.0.2
| | | | | \--- com.android.support:support-annotations:26.1.0 -> 27.0.2
| | | | +--- com.android.support:support-media-compat:27.0.2
| | | | | +--- com.android.support:support-annotations:27.0.2
| | | | | \--- com.android.support:support-compat:27.0.2
| | | | +--- com.android.support:support-core-utils:27.0.2
| | | | | +--- com.android.support:support-annotations:27.0.2
| | | | | \--- com.android.support:support-compat:27.0.2
| | | | +--- com.android.support:support-core-ui:27.0.2
| | | | | +--- com.android.support:support-annotations:27.0.2
| | | | | \--- com.android.support:support-compat:27.0.2
| | | | \--- com.android.support:support-fragment:27.0.2
| | | | +--- com.android.support:support-compat:27.0.2
| | | | +--- com.android.support:support-core-ui:27.0.2
| | | | +--- com.android.support:support-core-utils:27.0.2
| | | | \--- com.android.support:support-annotations:27.0.2
| | | \--- com.google.android.gms:play-services-basement-license:11.8.0
| | +--- com.google.firebase:firebase-common:11.8.0
| | | +--- com.google.android.gms:play-services-basement:11.8.0
| | | +--- com.google.android.gms:play-services-tasks:11.8.0
| | | | +--- com.google.android.gms:play-services-basement:11.8.0
| | | | \--- com.google.android.gms:play-services-tasks-license:11.8.0
| | | \--- com.google.firebase:firebase-common-license:11.8.0
| | +--- com.google.android.gms:play-services-tasks:11.8.0
| | \--- com.google.firebase:firebase-iid-license:11.8.0
| +--- com.google.android.gms:play-services-basement:11.8.0
| +--- com.google.firebase:firebase-common:11.8.0
| \--- com.google.firebase:firebase-messaging-license:11.8.0As you can see, this single dependency is pulling a ton of new ones. And this is where the lack of minification is hurting : even if you are taking great care of writing light code, declaring a single dependency would ruin all your efforts.
Regarding HQ Trivia, using a method count plugin for Gradle, we get the following graphs :
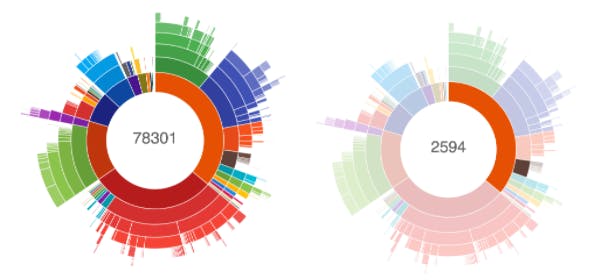
What they represent is that the whole project contains 78k methods, but only 2.6k methods are inside the package com.intermedia, which contains the code specific to HQ Trivia. There are also 186 methods in a com.tendigi package, which relate to the media player. In the end, that means that 96% of the methods in the project come from dependencies.
Third sample : lambdas and anonymous functions
As we previously mentioned, we could find hints that part of the code base was written in Kotlin. In theory, since Kotlin compiles to the same bytecode as Java, we should be unable to see the difference in the code. But Kotlin offers the possibility to write lambdas, which do not exist in Java. The way it works is during compilation, Kotlin will fallback on elements that do exist in Java bytecode, and lambdas no longer exist with that name in bytecode.
In our case, we are working from the bytecode, so we should not see any difference. Turns out, Kotlin-sourced bytecode can be tricky for Java decompilers, and they tend to fail on such idioms as lambda.
So you might find code that looks like this :
leaders.subscribe(
LeaderboardActivity..Lambda.0.get$Lambda(localLeaderboardAdapter),
LeaderboardActivity..Lambda.1.$instance
);The way Kotlin transforms lambdas and anonymous functions in bytecode is by creating classes that will wrap the code contained in those anonymous functions (you can find more information on the process here).
To find the code that should be the first argument of the subscribe method in our sample, we should take a look at the content of LeaderboardActivity$$Lambda$0 (the dots should be replaced by $). This code looks like this :
final class LeaderboardActivity$$Lambda$0 implements Consumer {
private final LeaderboardAdapter arg$1;
private LeaderboardActivity$$Lambda$0(final LeaderboardAdapter arg$1) {
this.arg$1 = arg$1;
}
static Consumer get$Lambda(final LeaderboardAdapter leaderboardAdapter) {
return (Consumer)new LeaderboardActivity$$Lambda$0(leaderboardAdapter);
}
public void accept(final Object o) {
this.arg$1.takeLeaderData((List)o);
}
}This is a very convoluted way of writing that the first argument of subscribe should look like this :
list -> localLeaderboardAdapter.takeLeaderData(list)Great ! Since the decompiler was having issues with those weirdly named classes (with all those dots), we can help it by inlining the content of those Lambda classes where they belong.
While this works with simple snippets (like our previous example), the problem becomes a lot more difficult in some cases. For example, in the same class, just a couple lines below, we find a call to LeaderboardActivity$$Lambda$2. The contents are as follows :
final class LeaderboardActivity$$Lambda$2 implements Consumer{
private final LeaderboardActivity arg$1;
LeaderboardActivity$$Lambda$2(final LeaderboardActivity arg$1) {
this.arg$1 = arg$1;
}
public void accept(final Object o) {
this.arg$1.lambda$onCreate$0$LeaderboardActivity((String)o);
}
}Instead of showing us what the lambda was supposed to do, we are sent back to a method of the caller class! This method should contain the body of our lambda, but it is nowhere to be seen. The reason is that our decompiler will always fail on decompiling those kind of redirections from lambdas.
One way to find the missing code would be to go back to the bytecode (or its smali version), and rewrite the Java code from this source. The process was described in a previous paragraph (“re-use of variables”). But this is a very tedious process, and would have been the end of our efforts.
Fortunately, a failure from our decompiler does not mean all decompilers will face the same issue. And it turns out that while Jadx or Procyon fail on those lambdas, CFR manages to find our missing methods. In it, we can see :
final /* synthetic */ void lambda$onCreate$0$LeaderboardActivity(String string)
throws Exception {
Picasso.with((Context)this).load(string).into(this.selfAvatarImageView);
}It seems that all methods declared synthetic in the bytecode trigger a failure in Jadx or Procyon, but CFR decompiles them without issue and simply flags them with a /* synthetic */ comment.
With the tricks shown in those samples, we now have all the tools required to fix all the issues in our decompiled project! There are still a lot of micro tasks to perform (replacing id numbers with their declarations, fixing imports, fixing other missing methods, …) but there is no longer any technical challenge.
And we did manage to make a new project from those sources that could compile to a new HQ Trivia app.
Conclusion
When we decided to take a look at the innards of HQ Trivia, we did not anticipate it could lead us that far.
Working around the API allowed us to progressively read, understand and finally interact with the trivia. The humble client we wrote in a few hours was enough for us to build a trivia history, priceless for anyone planning to level up its answering skills. Our experiment to build an automated player though showed that, thanks to thoughtfully crafted questions, cheaters would have a long way to go.
We then experimented the extent to which a simple .apk from the Play store could lead us. And without an intentional obfuscation from the developers, it’s quite far. With the help of efficient and user-friendly Java decompilation tools, we recovered a good part of the application codebase. To recreate the missing pieces of the jigsaw puzzle, we rolled up our sleeves and dived into Smali. Although tedious, this process allowed to recreate a full, compiling, Android application project.
If we stumbled upon unexpected technical choices (? RTSP stream), we did not unearth any magical technologies. HQ Trivia builds the quality of the experience of its application on proven, known to everybody, technologies. They simply employ them wisely.
If our findings vastly exceeded our expectations, our curiosity remains not completely sated. We would have loved to take a look at their back end architecture, as they face great challenges, like a close to real-time synchronization between a live video stream and websockets operating the questioning process (all of that for almost a million concurrent connections). However this time, we will have to wait for them to tell the story.